Congressional Influence - All
We take one last look at congressional bill sponsorship data. Whereas before we learned individual Bayesian Belief Networks (BBNs) for the districts in each individual states, this time, we learn a single BBN over all the districts and states.
Learning
To learn the network structure based on the Maximum Weight Spanning Tree (MWST) algorithm, we submitted a batch job to Google Cloud Platform’s (GCP) Dataproc. The script, learn.py, looks like the following.
import argparse
import json
import sys
from google.cloud import storage
from typing import List
import networkx as nx
import json
from typing import Dict, Any
from pyspark.sql import SparkSession
from pysparkbbn.discrete.bbn import get_darkstar_data, get_pybbn_data
from pysparkbbn.discrete.data import DiscreteData
from pysparkbbn.discrete.plearn import SmallDataParamLearner
from pysparkbbn.discrete.scblearn import Mwst
def save_json(data: Dict[Any, Any], blob_name: str, bucket='bucket-tmp'):
storage.Client() \
.get_bucket(bucket) \
.blob(blob_name) \
.upload_from_string(data=json.dumps(data), content_type='application/json')
def save_graph(g: nx.DiGraph, blob_name: str, bucket='bucket-tmp'):
local_path = '/tmp/graph.gexf'
nx.write_gexf(g, local_path)
with open(local_path, 'r') as fp:
storage.Client() \
.get_bucket(bucket) \
.blob(blob_name) \
.upload_from_file(fp, content_type='application/xml')
def parse_pargs(args: List[str]) -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument('--input', type=str, required=True, help='Input CSV file')
parser.add_argument('--bucket', type=str, required=False, help='Bucket', default='bucket-tmp')
parser.add_argument('--path', type=str, required=False, help='Path from bucket.', default='congress-influence')
return parser.parse_args(args)
def start(input_path: str, bucket: str, path: str):
spark = SparkSession \
.builder \
.appName('learn-naive') \
.getOrCreate()
print('built spark session')
sdf = spark.read \
.option('header', True) \
.option('inferSchema', True) \
.csv(input_path) \
.drop('legislation') \
.repartition(40)
print('loaded data into spark')
data = DiscreteData(sdf)
print('created data')
mwst = Mwst(data)
g = mwst.get_network()
print('learned graph structure')
save_graph(g, f'{path}/graph.gexf', bucket)
param_learner = SmallDataParamLearner(data, g)
p = param_learner.get_params()
print('learned graph parameters')
save_json(p, f'{path}/p.json', bucket)
pybbn_data = get_pybbn_data(g, p, data.get_profile())
save_json(pybbn_data, f'{path}/pybbn.json', bucket)
print('saved pybbn json')
darkstar_data = get_darkstar_data(g, p, data.get_profile())
save_json(darkstar_data, f'{path}/darkstar.json', bucket)
print('saved darkstar json')
print('finished')
if __name__ == '__main__':
args = parse_pargs(sys.argv[1:])
input_path = args.input
bucket = args.bucket
path = args.path
start(input_path, bucket, path)
The submission of the job was executed as follows.
gcloud dataproc batches submit pyspark \
learn.py \
--async \
--region=some-region \
--version=2.0 \
--properties=spark.app.name="congress-influence",spark.default.parallelism=10,spark.driver.cores=4,spark.driver.maxResultSize=90g,spark.driver.memory=6g,spark.dynamicAllocation.enabled=true,spark.dynamicAllocation.executorAllocationRatio=1.0,spark.dynamicAllocation.initialExecutors=10,spark.dynamicAllocation.minExecutors=10,spark.dynamicAllocation.maxExecutors=36,spark.executor.cores=4,spark.executor.instances=10,spark.executor.memory=16g \
--deps-bucket=my-gcs-dep-bucket \
--py-files=pybbn-3.2.3-py3.9.egg,pysparkbbn-0.0.4-py3.9.egg \
-- --input gs://bucket-data/data/congress-influence.csv
The total learning time took under 13 minutes.
Structure
The structure of the BBN is shown below. Since this network structure is a tree, there are 441 nodes and 440 (directed) edges.
[103]:
import networkx as nx
g = nx.read_gexf('./data/congress-influence.gexf')
[105]:
len(g.nodes()), len(g.edges())
[105]:
(441, 440)
[2]:
pos = nx.nx_pydot.graphviz_layout(g, prog='dot')
[3]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(50, 20))
nx.draw_networkx_nodes(
G=g,
pos=pos,
ax=ax,
node_size=10,
node_color='#2eb82e',
alpha=0.4,
margins=(0.01, 0.01)
)
nx.draw_networkx_labels(
G=g,
pos=pos,
font_size=10,
font_color='r',
ax=ax
)
nx.draw_networkx_edges(
G=g,
pos=pos,
ax=ax,
arrowsize=15,
alpha=0.5
)
fig.tight_layout()
Influence
The BBN learned serialized into JSON format is pretty large (slightly over 1 GB). Loading the data takes about 1.5 minutes and computing all the posteriors takes about 30 seconds. When using R’s implementations with bnlearn and gRain for exact inference, it takes over 10 minutes just to deserialize the model.
[1]:
from darkstar.inference import from_json
import pandas as pd
def get_posteriors(m, sponsorship=1):
p = {n: m.get_posterior_by_name(n) for n in m.get_node_names()}
p = pd.Series({k: v[sponsorship]['p'] for k, v in p.items()}, dtype=float)
return p
[106]:
%%time
m = from_json('./data/congress-influence-all-darkstar-tree.json')
CPU times: user 1min 22s, sys: 7.78 s, total: 1min 30s
Wall time: 1min 32s
[107]:
%%time
_p0 = get_posteriors(m)
CPU times: user 29.8 s, sys: 324 ms, total: 30.1 s
Wall time: 30.1 s
[20]:
meta_pdf = pd.read_csv('./data/congress-meta.csv', low_memory=False) \
.assign(state=lambda d: d['district'].apply(lambda s: s.split('_')[0])) \
.set_index(['district'])
meta_pdf.shape
[20]:
(441, 3)
[4]:
evidences = [{d: {'yes': 1.0, 'no': 0.0}} for d, r in meta_pdf.iterrows()]
len(evidences)
[4]:
441
[6]:
from pathlib import Path
for i, e in enumerate(evidences):
_district = list(e.keys())[0]
path = f'./data/influence/{_district}.csv'
print(f'{i:03} | {_district} > ', end=' ')
if Path(path).exists():
continue
m.clear_evidences()
m.assert_evidences_by_name(e)
_p1 = get_posteriors(m)
_df = pd.DataFrame({'p_0': _p0, 'p_1': _p1}) \
.assign(lift=lambda d: d.p_1 / d.p_0)
_df.to_csv(path)
print('')
000 | AK_99 > 001 | AL_01 > 002 | AL_02 > 003 | AL_03 > 004 | AL_04 > 005 | AL_05 > 006 | AL_06 > 007 | AL_07 > 008 | AR_01 > 009 | AR_02 > 010 | AR_03 > 011 | AR_04 > 012 | AS_99 > 013 | AZ_01 > 014 | AZ_02 > 015 | AZ_03 > 016 | AZ_04 > 017 | AZ_05 > 018 | AZ_06 > 019 | AZ_07 > 020 | AZ_08 > 021 | AZ_09 > 022 | CA_01 > 023 | CA_02 > 024 | CA_03 > 025 | CA_04 > 026 | CA_05 > 027 | CA_06 > 028 | CA_07 > 029 | CA_08 > 030 | CA_09 > 031 | CA_10 > 032 | CA_11 > 033 | CA_12 > 034 | CA_13 > 035 | CA_14 > 036 | CA_15 > 037 | CA_16 > 038 | CA_17 > 039 | CA_18 > 040 | CA_19 > 041 | CA_20 > 042 | CA_21 > 043 | CA_22 > 044 | CA_23 > 045 | CA_24 > 046 | CA_25 > 047 | CA_26 > 048 | CA_27 > 049 | CA_28 > 050 | CA_29 > 051 | CA_30 > 052 | CA_31 > 053 | CA_32 > 054 | CA_33 > 055 | CA_34 > 056 | CA_35 > 057 | CA_36 > 058 | CA_37 > 059 | CA_38 > 060 | CA_39 > 061 | CA_40 > 062 | CA_41 > 063 | CA_42 > 064 | CA_43 > 065 | CA_44 > 066 | CA_45 > 067 | CA_46 > 068 | CA_47 > 069 | CA_48 > 070 | CA_49 > 071 | CA_50 > 072 | CA_51 > 073 | CA_52 > 074 | CO_01 > 075 | CO_02 > 076 | CO_03 > 077 | CO_04 > 078 | CO_05 > 079 | CO_06 > 080 | CO_07 > 081 | CO_08 > 082 | CT_01 > 083 | CT_02 > 084 | CT_03 > 085 | CT_04 > 086 | CT_05 > 087 | DC_99 > 088 | DE_99 > 089 | FL_01 > 090 | FL_02 > 091 | FL_03 > 092 | FL_04 > 093 | FL_05 > 094 | FL_06 > 095 | FL_07 > 096 | FL_08 > 097 | FL_09 > 098 | FL_10 > 099 | FL_11 > 100 | FL_12 > 101 | FL_13 > 102 | FL_14 > 103 | FL_15 > 104 | FL_16 > 105 | FL_17 > 106 | FL_18 > 107 | FL_19 > 108 | FL_20 > 109 | FL_21 > 110 | FL_22 > 111 | FL_23 > 112 | FL_24 > 113 | FL_25 > 114 | FL_26 > 115 | FL_27 > 116 | FL_28 > 117 | GA_01 > 118 | GA_02 > 119 | GA_03 > 120 | GA_04 > 121 | GA_05 > 122 | GA_06 > 123 | GA_07 > 124 | GA_08 > 125 | GA_09 > 126 | GA_10 > 127 | GA_11 > 128 | GA_12 > 129 | GA_13 > 130 | GA_14 > 131 | GU_99 > 132 | HI_01 > 133 | HI_02 > 134 | IA_01 > 135 | IA_02 > 136 | IA_03 > 137 | IA_04 > 138 | ID_01 > 139 | ID_02 > 140 | IL_01 > 141 | IL_02 > 142 | IL_03 > 143 | IL_04 > 144 | IL_05 > 145 | IL_06 > 146 | IL_07 > 147 | IL_08 > 148 | IL_09 > 149 | IL_10 > 150 | IL_11 > 151 | IL_12 > 152 | IL_13 > 153 | IL_14 > 154 | IL_15 > 155 | IL_16 > 156 | IL_17 > 157 | IN_01 > 158 | IN_02 > 159 | IN_03 > 160 | IN_04 > 161 | IN_05 > 162 | IN_06 > 163 | IN_07 > 164 | IN_08 > 165 | IN_09 > 166 | KS_01 > 167 | KS_02 > 168 | KS_03 > 169 | KS_04 > 170 | KY_01 > 171 | KY_02 > 172 | KY_03 > 173 | KY_04 > 174 | KY_05 > 175 | KY_06 > 176 | LA_01 > 177 | LA_02 > 178 | LA_03 > 179 | LA_04 > 180 | LA_05 > 181 | LA_06 > 182 | MA_01 > 183 | MA_02 > 184 | MA_03 > 185 | MA_04 > 186 | MA_05 > 187 | MA_06 > 188 | MA_07 > 189 | MA_08 > 190 | MA_09 > 191 | MD_01 > 192 | MD_02 > 193 | MD_03 > 194 | MD_04 > 195 | MD_05 > 196 | MD_06 > 197 | MD_07 > 198 | MD_08 > 199 | ME_01 > 200 | ME_02 > 201 | MI_01 > 202 | MI_02 > 203 | MI_03 > 204 | MI_04 > 205 | MI_05 > 206 | MI_06 > 207 | MI_07 > 208 | MI_08 > 209 | MI_09 > 210 | MI_10 > 211 | MI_11 > 212 | MI_12 > 213 | MI_13 > 214 | MN_01 > 215 | MN_02 > 216 | MN_03 > 217 | MN_04 > 218 | MN_05 > 219 | MN_06 > 220 | MN_07 > 221 | MN_08 > 222 | MO_01 > 223 | MO_02 > 224 | MO_03 > 225 | MO_04 > 226 | MO_05 > 227 | MO_06 > 228 | MO_07 > 229 | MO_08 > 230 | MP_99 > 231 | MS_01 > 232 | MS_02 > 233 | MS_03 > 234 | MS_04 > 235 | MT_01 > 236 | MT_02 > 237 | NC_01 > 238 | NC_02 > 239 | NC_03 > 240 | NC_04 > 241 | NC_05 > 242 | NC_06 > 243 | NC_07 > 244 | NC_08 > 245 | NC_09 > 246 | NC_10 > 247 | NC_11 > 248 | NC_12 > 249 | NC_13 > 250 | NC_14 > 251 | ND_99 > 252 | NE_01 > 253 | NE_02 > 254 | NE_03 > 255 | NH_01 > 256 | NH_02 > 257 | NJ_01 > 258 | NJ_02 > 259 | NJ_03 > 260 | NJ_04 > 261 | NJ_05 > 262 | NJ_06 > 263 | NJ_07 > 264 | NJ_08 > 265 | NJ_09 > 266 | NJ_10 > 267 | NJ_11 > 268 | NJ_12 > 269 | NM_01 > 270 | NM_02 > 271 | NM_03 > 272 | NV_01 > 273 | NV_02 > 274 | NV_03 > 275 | NV_04 > 276 | NY_01 > 277 | NY_02 > 278 | NY_03 > 279 | NY_04 > 280 | NY_05 > 281 | NY_06 > 282 | NY_07 > 283 | NY_08 > 284 | NY_09 > 285 | NY_10 > 286 | NY_11 > 287 | NY_12 > 288 | NY_13 > 289 | NY_14 > 290 | NY_15 > 291 | NY_16 > 292 | NY_17 > 293 | NY_18 > 294 | NY_19 > 295 | NY_20 > 296 | NY_21 > 297 | NY_22 > 298 | NY_23 > 299 | NY_24 > 300 | NY_25 > 301 | NY_26 > 302 | OH_01 > 303 | OH_02 > 304 | OH_03 > 305 | OH_04 > 306 | OH_05 > 307 | OH_06 > 308 | OH_07 > 309 | OH_08 > 310 | OH_09 > 311 | OH_10 > 312 | OH_11 > 313 | OH_12 > 314 | OH_13 > 315 | OH_14 > 316 | OH_15 > 317 | OK_01 > 318 | OK_02 > 319 | OK_03 > 320 | OK_04 > 321 | OK_05 > 322 | OR_01 > 323 | OR_02 > 324 | OR_03 > 325 | OR_04 > 326 | OR_05 > 327 | OR_06 > 328 | PA_01 > 329 | PA_02 > 330 | PA_03 > 331 | PA_04 > 332 | PA_05 > 333 | PA_06 > 334 | PA_07 > 335 | PA_08 > 336 | PA_09 > 337 | PA_10 > 338 | PA_11 > 339 | PA_12 > 340 | PA_13 > 341 | PA_14 > 342 | PA_15 > 343 | PA_16 > 344 | PA_17 > 345 | PR_99 > 346 | RI_01 > 347 | RI_02 > 348 | SC_01 > 349 | SC_02 > 350 | SC_03 > 351 | SC_04 > 352 | SC_05 > 353 | SC_06 > 354 | SC_07 > 355 | SD_99 > 356 | TN_01 > 357 | TN_02 > 358 | TN_03 > 359 | TN_04 > 360 | TN_05 > 361 | TN_06 > 362 | TN_07 > 363 | TN_08 > 364 | TN_09 > 365 | TX_01 > 366 | TX_02 > 367 | TX_03 > 368 | TX_04 > 369 | TX_05 > 370 | TX_06 > 371 | TX_07 > 372 | TX_08 > 373 | TX_09 > 374 | TX_10 > 375 | TX_11 > 376 | TX_12 > 377 | TX_13 > 378 | TX_14 > 379 | TX_15 > 380 | TX_16 > 381 | TX_17 > 382 | TX_18 > 383 | TX_19 > 384 | TX_20 > 385 | TX_21 > 386 | TX_22 > 387 | TX_23 > 388 | TX_24 > 389 | TX_25 > 390 | TX_26 > 391 | TX_27 > 392 | TX_28 > 393 | TX_29 > 394 | TX_30 > 395 | TX_31 > 396 | TX_32 > 397 | TX_33 > 398 | TX_34 > 399 | TX_35 > 400 | TX_36 > 401 | TX_37 > 402 | TX_38 > 403 | UT_01 > 404 | UT_02 > 405 | UT_03 > 406 | UT_04 > 407 | VA_01 > 408 | VA_02 > 409 | VA_03 > 410 | VA_04 > 411 | VA_05 > 412 | VA_06 > 413 | VA_07 > 414 | VA_08 > 415 | VA_09 > 416 | VA_10 > 417 | VA_11 > 418 | VI_99 > 419 | VT_99 > 420 | WA_01 > 421 | WA_02 > 422 | WA_03 > 423 | WA_04 > 424 | WA_05 > 425 | WA_06 > 426 | WA_07 > 427 | WA_08 > 428 | WA_09 > 429 | WA_10 > 430 | WI_01 > 431 | WI_02 > 432 | WI_03 > 433 | WI_04 > 434 | WI_05 > 435 | WI_06 > 436 | WI_07 > 437 | WI_08 > 438 | WV_01 > 439 | WV_02 > 440 | WY_99 >
[43]:
def read_data(p):
df = pd.read_csv(p, index_col=0) \
.reset_index() \
.rename(columns={'index': 'district'}) \
s = meta_pdf.loc[p.stem]
return df.assign(
district_state=lambda d: d['district'].apply(lambda d: d.split('_')[0]),
district_party=lambda d: d['district'].apply(lambda d: meta_pdf.loc[d]['party']),
district_name=lambda d: d['district'].apply(lambda d: meta_pdf.loc[d]['name']),
influence_district=p.stem,
influence_state=s.state,
influence_name=s['name'],
influence_party=s.party
)
df = (p for p in Path('./data/influence').glob('*.csv'))
df = map(read_data, df)
df = pd.concat(df)
df.shape
[43]:
(194481, 11)
Cross-party influence
Here, we look at cross-party influences. As shown above, we compute the sponsorship lift for every congressional district against the others. Keeping only sponsorship lift greater than 1.0, we then cross-tabulate cross-party influence between the two parties (D = Democat, R = Republican). As you can see below, party alignment is very strong; democrats provide sponsorship lift to other democrats 57% of the time (over all the bills); republicans provide sponsorship lift to other republicans 42% of the time. The members of each party provide insignificant marginal lift to the opposing party.
[108]:
_df = df \
.query('lift > 1.0') \
.query('district != influence_district') \
.sort_values(['influence_district', 'lift'], ascending=[True, False]) \
[['district', 'district_party', 'district_name', 'district_state',
'influence_district', 'influence_party', 'influence_name', 'influence_state', 'lift']]
[94]:
import seaborn as sns
ax = sns.heatmap(
pd.crosstab(_df['district_party'], _df['influence_party']) / _df.shape[0],
cmap=sns.light_palette('seagreen', as_cmap=True),
annot=True)
_ = ax.set_title('Cross-party influence')
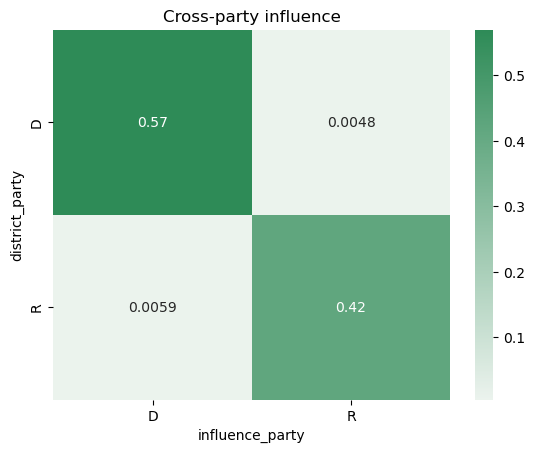
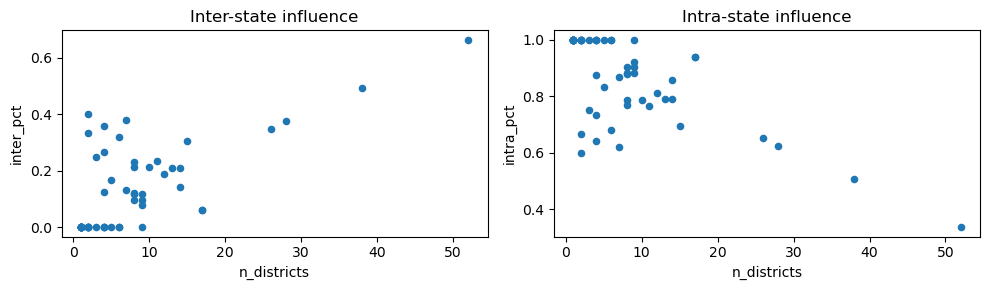
Within and between state influence
The two graphs below are complementary and show the inter- and intra-state influences (as defined by lift being greater than 1.0). You can see that as the number of district increases for a state, the inter-state (within) influence is greater and the intra-state is lesser. Bill sponsorship seem to also align with geography (or state of origin).
[83]:
import numpy as np
_ct = pd.crosstab(_df['district_state'], _df['influence_state']) \
.assign(
inter=np.diag(pd.crosstab(_df['district_state'], _df['influence_state'])),
margin=pd.crosstab(_df['district_state'], _df['influence_state']).apply(sum, axis=1),
inter_pct=lambda d: d['inter'] / d['margin'],
intra_pct=lambda d: 1 - d['inter_pct'],
n_districts=meta_pdf.groupby(['state']).size()
)[['inter_pct', 'intra_pct', 'n_districts']] \
.sort_values(['inter_pct', 'intra_pct'], ascending=False)
[95]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
_ct.plot(kind='scatter', x='n_districts', y='inter_pct', ax=ax[0])
_ct.plot(kind='scatter', x='n_districts', y='intra_pct', ax=ax[1])
ax[0].set_title('Inter-state influence')
ax[1].set_title('Intra-state influence')
fig.tight_layout()
/opt/anaconda3/lib/python3.9/site-packages/pandas/plotting/_matplotlib/core.py:1114: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
scatter = ax.scatter(
Largest lift, different districts
The table below shows the top largest lift when the districts are different for the influencer and influenced Congress members. As can be seen below, Roger Williams generates tremendous sponsorship lift to Mike Johnson.
[115]:
_df[(_df['influence_district'] != _df['district'])] \
.sort_values(['lift'], ascending=False) \
[['district', 'district_name', 'influence_district', 'influence_name', 'lift']] \
.head(20)
[115]:
| district | district_name | influence_district | influence_name | lift | |
|---|---|---|---|---|---|
| 179 | LA_04 | Mike Johnson | TX_25 | Roger Williams | 3772.000000 |
| 214 | MN_01 | Brad Finstad | MN_08 | Pete Stauber | 1397.000000 |
| 214 | MN_01 | Brad Finstad | NE_01 | Mike Flood | 1028.000000 |
| 352 | SC_05 | Ralph Norman | SC_04 | William R Timmons | 793.714286 |
| 214 | MN_01 | Brad Finstad | MO_04 | Mark Alford | 636.000000 |
| 352 | SC_05 | Ralph Norman | SC_02 | Joe Wilson | 597.571429 |
| 179 | LA_04 | Mike Johnson | LA_06 | Garret Graves | 371.000000 |
| 179 | LA_04 | Mike Johnson | AL_03 | Mike D Rogers | 304.000000 |
| 214 | MN_01 | Brad Finstad | MN_06 | Tom Emmer | 173.000000 |
| 214 | MN_01 | Brad Finstad | MO_02 | Ann Wagner | 124.000000 |
| 186 | MA_05 | Katherine M Clark | MD_05 | Steny H Hoyer | 70.186782 |
| 195 | MD_05 | Steny H Hoyer | MA_05 | Katherine M Clark | 70.078481 |
| 214 | MN_01 | Brad Finstad | WI_08 | Mike Gallagher | 62.000000 |
| 179 | LA_04 | Mike Johnson | MO_03 | Blaine Luetkemeyer | 59.000000 |
| 352 | SC_05 | Ralph Norman | SC_01 | Nancy Mace | 52.428571 |
| 268 | NJ_12 | Bonnie Watson Coleman | NJ_10 | Donald M Payne | 32.444444 |
| 46 | CA_25 | Raul Ruiz | CA_11 | Nancy Pelosi | 31.170072 |
| 32 | CA_11 | Nancy Pelosi | CA_25 | Raul Ruiz | 31.159722 |
| 275 | NV_04 | Steven Horsford | SC_06 | James E Clyburn | 29.946565 |
| 353 | SC_06 | James E Clyburn | NV_04 | Steven Horsford | 29.942127 |
Largest lift, different parties
The table below shows the top largest lift when the parties are different for the influencer and influenced Congress members. As can be seen below, Aumua Amata Radewagen generates the highest cross-party sponsorship lift to Gregorio Kilili Sablan.
[127]:
_df[(_df['influence_party'] != _df['district_party'])] \
.sort_values(['lift'], ascending=False) \
[['district', 'district_name', 'district_party', 'influence_district', 'influence_name', 'influence_party', 'lift']] \
.head(15) \
.query('lift > 1.1')
[127]:
| district | district_name | district_party | influence_district | influence_name | influence_party | lift | |
|---|---|---|---|---|---|---|---|
| 230 | MP_99 | Gregorio Kilili Sablan | D | AS_99 | Aumua Amata Radewagen | R | 13.519681 |
| 12 | AS_99 | Aumua Amata Radewagen | R | MP_99 | Gregorio Kilili Sablan | D | 13.513704 |
| 131 | GU_99 | James C Moylan | R | MP_99 | Gregorio Kilili Sablan | D | 4.184179 |
| 230 | MP_99 | Gregorio Kilili Sablan | D | GU_99 | James C Moylan | R | 4.184161 |
| 322 | OR_01 | Suzanne Bonamici | D | AS_99 | Aumua Amata Radewagen | R | 2.043744 |
| 12 | AS_99 | Aumua Amata Radewagen | R | OR_01 | Suzanne Bonamici | D | 2.043070 |
| 61 | CA_40 | Young Kim | R | CA_06 | Ami Bera | D | 1.786346 |
| 328 | PA_01 | Brian K Fitzpatrick | R | NJ_05 | Josh Gottheimer | D | 1.584994 |
| 131 | GU_99 | James C Moylan | R | OR_01 | Suzanne Bonamici | D | 1.265643 |
| 322 | OR_01 | Suzanne Bonamici | D | GU_99 | James C Moylan | R | 1.265419 |
| 328 | PA_01 | Brian K Fitzpatrick | R | MD_06 | David J Trone | D | 1.248712 |
| 196 | MD_06 | David J Trone | D | PA_01 | Brian K Fitzpatrick | R | 1.248675 |
| 268 | NJ_12 | Bonnie Watson Coleman | D | PA_01 | Brian K Fitzpatrick | R | 1.111111 |
Largest lift, different states
The table below shows the top largest lift when the states are different for the influencer and influenced Congress members.
[122]:
_df[(_df['influence_state'] != _df['district_state'])] \
.sort_values(['lift'], ascending=False) \
[['district', 'district_name', 'district_state', 'influence_district', 'influence_name', 'influence_state', 'lift']] \
.head(15)
[122]:
| district | district_name | district_state | influence_district | influence_name | influence_state | lift | |
|---|---|---|---|---|---|---|---|
| 179 | LA_04 | Mike Johnson | LA | TX_25 | Roger Williams | TX | 3772.000000 |
| 214 | MN_01 | Brad Finstad | MN | NE_01 | Mike Flood | NE | 1028.000000 |
| 214 | MN_01 | Brad Finstad | MN | MO_04 | Mark Alford | MO | 636.000000 |
| 179 | LA_04 | Mike Johnson | LA | AL_03 | Mike D Rogers | AL | 304.000000 |
| 214 | MN_01 | Brad Finstad | MN | MO_02 | Ann Wagner | MO | 124.000000 |
| 186 | MA_05 | Katherine M Clark | MA | MD_05 | Steny H Hoyer | MD | 70.186782 |
| 195 | MD_05 | Steny H Hoyer | MD | MA_05 | Katherine M Clark | MA | 70.078481 |
| 214 | MN_01 | Brad Finstad | MN | WI_08 | Mike Gallagher | WI | 62.000000 |
| 179 | LA_04 | Mike Johnson | LA | MO_03 | Blaine Luetkemeyer | MO | 59.000000 |
| 275 | NV_04 | Steven Horsford | NV | SC_06 | James E Clyburn | SC | 29.946565 |
| 353 | SC_06 | James E Clyburn | SC | NV_04 | Steven Horsford | NV | 29.942127 |
| 268 | NJ_12 | Bonnie Watson Coleman | NJ | NY_09 | Yvette D Clarke | NY | 29.333333 |
| 268 | NJ_12 | Bonnie Watson Coleman | NJ | MA_06 | Seth Moulton | MA | 29.000000 |
| 214 | MN_01 | Brad Finstad | MN | OK_03 | Frank D Lucas | OK | 28.000000 |
| 214 | MN_01 | Brad Finstad | MN | WI_03 | Derrick Van Orden | WI | 28.000000 |
Largest lift, different district, party, state
The table below shows the top largest lift when the district, party and state are different for the influencer and influenced Congress members.
[126]:
_f = (_df['influence_district'] != _df['district'])
_f = (_f) & (_df['influence_party'] != _df['district_party'])
_f = (_f) & (_df['influence_state'] != _df['district_state'])
_df[_f] \
.sort_values(['lift'], ascending=False) \
.query('lift > 1.1')
[126]:
| district | district_party | district_name | district_state | influence_district | influence_party | influence_name | influence_state | lift | |
|---|---|---|---|---|---|---|---|---|---|
| 230 | MP_99 | D | Gregorio Kilili Sablan | MP | AS_99 | R | Aumua Amata Radewagen | AS | 13.519681 |
| 12 | AS_99 | R | Aumua Amata Radewagen | AS | MP_99 | D | Gregorio Kilili Sablan | MP | 13.513704 |
| 131 | GU_99 | R | James C Moylan | GU | MP_99 | D | Gregorio Kilili Sablan | MP | 4.184179 |
| 230 | MP_99 | D | Gregorio Kilili Sablan | MP | GU_99 | R | James C Moylan | GU | 4.184161 |
| 322 | OR_01 | D | Suzanne Bonamici | OR | AS_99 | R | Aumua Amata Radewagen | AS | 2.043744 |
| 12 | AS_99 | R | Aumua Amata Radewagen | AS | OR_01 | D | Suzanne Bonamici | OR | 2.043070 |
| 328 | PA_01 | R | Brian K Fitzpatrick | PA | NJ_05 | D | Josh Gottheimer | NJ | 1.584994 |
| 131 | GU_99 | R | James C Moylan | GU | OR_01 | D | Suzanne Bonamici | OR | 1.265643 |
| 322 | OR_01 | D | Suzanne Bonamici | OR | GU_99 | R | James C Moylan | GU | 1.265419 |
| 328 | PA_01 | R | Brian K Fitzpatrick | PA | MD_06 | D | David J Trone | MD | 1.248712 |
| 196 | MD_06 | D | David J Trone | MD | PA_01 | R | Brian K Fitzpatrick | PA | 1.248675 |
| 268 | NJ_12 | D | Bonnie Watson Coleman | NJ | PA_01 | R | Brian K Fitzpatrick | PA | 1.111111 |